
標本調査では、必ずと言っていいほど、何らかの誤差が発生します。そうした誤差は、時に真実とは異なる「観測結果」をもたらし、判断や認識を誤らせる原因となります。本稿では、まず、そうした誤差の種類について説明し、続いて、誤差を評価する際の3つの観点、精度、正確性、妥当性について解説していきます。
なお、閲覧にあたっては、以下の点にご注意ください。
- スマートフォンやタブレット端末でご覧の際、数式が見切れている場合は、横にスクロールすることができます。
誤差の種類
誤差には、「偶然に起こるもの」と「系統的に起こるもの」があり、前者を偶然誤差、後者を系統誤差といいます。
偶然誤差
偶然誤差 random error とは、偶然によって生じる誤差(測定値のばらつき)のことで、対象者が本質的に持っているばらつきと測定時に発生するばらつきがあります。
「対象者が本質的に持っているばらつき」とは、例えば、「個人ごとに身長や体重が異なる」ということで、それを「平均」という1つの値からの「ズレ」としてとらえることから生じるばらつきです。
「測定時に発生するばらつき」とは、例えば、身長計の目盛りを読む際に、小数点以下の値をどう判断するかによって生じるばらつきです。また、身長を測る時間帯によっても差が生じますが、これも測定時に発生するばらつきといえます。
偶然誤差は、サンプルサイズが大きくなればなるほど小さくなり、極限的には0にすることが可能であることが特徴です。そのため、全数調査では、偶然誤差は生じません。
標本抽出変動
研究を標本調査で実施する場合、研究の対象であるターゲット集団から観察対象集団を無作為に抽出するのが原則ですが、複数の標本抽出を行った場合、標本ごとに異なる結果が観察されることは容易に想像できます。これを標本抽出変動と呼びます。統計学的推定や検定などの統計学的推論は、確率論を用いて偶然誤差の大きさを評価したものです。
系統誤差(バイアス)
偶然誤差とは異なり、系統的な、一定の方向性をもった誤差を系統誤差 systematic error、あるいは偏り(バイアス) bias といいます。系統誤差は、偶然誤差とは異なり、サンプルサイズを大きくしても解消することができないことが特徴です。研究のサイズが大きくなり、偶然誤差が減少するにつれ、系統誤差の相対的な役割は大きくなります。研究が十分大きい場合、憂慮すべき誤差は事実上、すべて系統誤差ということになります。
系統誤差は、「誤差のうち、標本抽出変動を除いたすべてのもの」であり、大きく分けると、①選択バイアス、②情報バイアス、③交絡に大別されます。このうち、交絡は解析段階でも制御(影響を最小限にすること)可能ですが、選択バイアスと情報バイアスは、解析段階では制御できず、研究計画段階できちんと制御することを考慮しておく必要があります。
各バイアスの詳しい内容は別稿で解説することとし、本稿では、こうした誤差を評価する際の3つの観点、精度、正確性、妥当性について解説していきます。
精度
定義
精度 precision とは、測定の安定性(再現性)や測定結果の変動(ばらつき)を表す概念で、偶然誤差の大きさを評価するためのものです。再現性 reproducibility, repeatability、信頼性 reliability、一致度 consistency ということもあります。
たとえば、同じ人が5分間に何回か体重計で体重を測れば、どの測定結果もほぼ同じ結果になると思われます。いっぽう、例えばある人のQOLを面接調査で評価しようとすると、測定者(面接をする人)によって、評価が異なることがあり得ます。こうした例で、ばらつきが小さい場合を「精度が高い」、大きな場合を「精度が低い」と表現し、優れた評価尺度には、定められている方法通りに行えば、誰が評価しても、何回評価しても同じ結果が出ることが要求されます。
精度は研究の統計学的検出力に影響し、測定の精度が高ければ高いほど検出力は大きくなり、平均値の推定や、仮説検定に必要なサンプルサイズは小さくて済みます。
偶然誤差の原因
測定に伴って生じる偶然誤差は、以下の3つに大別されます。
測定者による誤差
測定者による誤差 observer variability は、測定者自身が原因となって生じる測定結果の誤差(変動)のことで、面接調査における質問の言葉遺いや測定機器を用いるときの技術などがその原因となります。
測定手段による誤差
測定手段による誤差 instrument variability は、測定手段が原因となって生じる誤差で、たとえば温度などの環境要因、機器部品の劣化、試薬のロットの違いなどによって生じます。
対象者による誤差
対象者による誤差 subject variability は、対象者自身の身体内部の状態などに起因する測定結果の誤差のことで、測定が行われる時間、最後の食事や服薬からの時間など、研究対象とする変数とは無関係に生じる誤差のことをいいます。
精度の評価
精度は、同じ測定者が同じ対象者あるいは検体について同じ測定を繰り返した場合(within-observer reproducibility)、あるいは異なる測定者が同じ対象者あるいは検体について同じ測定を実施した場合(between observer reproducibility)の結果の一致度(再現性)として評価されます。また、測定手段(質問票や測定機器)についても、同じ測定手段内、もしくは異なる測定手段間で精度を評価することができます。
連続変数の測定の再現性の指標には、対象者内標準偏差 within-subject standard deviation、あるいは、変動係数 coefficient of variation が用いられます。
カテゴリー変数の場合には、一致率(割合) percent agreement、級内相関係数 intraclass correlation coefficient やカッパ係数 kappa statistic がよく用いられます。
精度を向上させる方法
偶然誤差を減らし、測定の精度を向上させるには5つの方法があります。
- 1.測定方法の標準化
- 研究プロトコルには、測定の手順を必ず記述しなければなりません。つまり、測定環境や測定対象をどのように準備するのか、面接をどのように実施し記録するのか、測定手段(質問票や分析機器など)をどのように較正するのかなどについて、明確に記載する必要があります。大規模な研究でこのような実施マニュアルを作成することは当然ですが、小規模な研究でもできるだけ作成することが望まれます。たとえ1人で研究を行う場合でも、そうしたマニュアルがあれば、測定方法の質を研究期間中一定に保つことができ、また論文に方法論を書くときにも役立ちます。
- 2.測定スタッフのトレーニングと技能チェック
- 複数の測定スタッフが関わる場合には、測定方法を統一(標準化)するためのトレーニングが必要となります。そして、正式な技能チェックを行い、マニュアル通りに測定が実施されているかどうか、測定スタッフが必要なレベルの技能をマスターしているかどうかを確認しなければなりません。
- 3.測定手段の改善
- 測定の変動は、分析機器であれば機械的な調整を行うことによって、質問票や面接の場合は、質問を明解に表記することによって、変動を小さくすることができます。
- 4.測定手段の自動(自記)化
- 測定者自身に由来する測定の変動を減らすためには、分析機器の自動化や、質問票を自記式にするなどの方法があります。
- 5.測定の反復
- 測定を何度か繰り返して、その平均値をデータとして用いれば、偶然誤差の影響を減らすことができます。この方法を用いると、精度はかなり向上しますが、時間や経費の増加が問題となり、また、測定を繰り返すことが実際上困難な場合もあります。
正確性
定義
正確性 accuracy とは、測定値が、目的とする真の値(現象)にどれほど近い値をとるか、その程度を表す概念です。正確性と精度は異なる概念で、必ずしも関連した概念ではありません。たとえば、うっかり2倍に薄めた標準液を使って、血清コレステロールを測定したような場合には、正確性は低く(常に真値の2倍の値になる)、精度は高いということが起こります。しかし、現実には正確性と精度は一緒に変化することが多く、精度を高める対策の多くは正確性も同時に高めます。
正確性に関連するバイアスの種類
正確性は、バイアス(系統誤差)の影響を受け、バイアスが大きいほど、その変数の正確性は低下します。精度の場合と同じように、バイアスをその発生源の観点から、以下の3つに大別することができます。
測定者バイアス
測定者バイアス observer bias は、測定者が測定情報を故意、あるいは無意識に歪めて認識したり報告したりすることによって生じるバイアスです。例えば、患者の血圧を低めに読んでしまう傾向やインタビューをする際に誘導質問をすることなどがそれに当たります。
測定手段バイアス
測定手段バイアス instrument bias は、測定手段(測定機器や質問票)が原因となって生じるバイアスです。測定機器の調整不良がその典型的な例で、較正されていない体重計では、常に体重が実際より低め(あるいは高め)に表示されることがあります。
対象者バイアス
対象者バイアス subject bias は、研究対象者が原因となって生じるバイアスのことで、ある質問に対する回答に、系統的にバイアスが持ち込まれることをいいます(応答バイアス、もしくは想起バイアスともいいます)。たとえば、アルコール摂取ががんの原因と信じている乳がん患者は、アルコール摂取量を実際より多めに報告する傾向があるといったことです。
正確性の評価
測定値の正確性は、コールドスタンダード(真の値を測定できると考えられる方法で測られた標準値)との比較で評価するのが理想的です。どういう測定をゴールドスタンダードとするかの判断は、必ずしも簡単ではありませんが、過去の研究などを参考にして決定します。
連続変数(例:体重)の正確性は、同じ対象者について、研究で用いる測定法で得られた値とゴールドスタンダードとなる測定法で測られた値の平均値の差を求めることで評価することができます。
いっぽう、2区分変数の場合は、ゴールドスタンダードとの比較は、感度と特異度として表現されます。区分が3つ以上のカテゴリー変数の場合には、各項目の正答率によって評価します。
正確性を向上させる方法
正確性を向上させるための主な対策には、前に精度のところで説明した1~4に加え、以下に述べる3つの対策があります。
- 1.測定方法の標準化
- 2.測定スタッフのトレーニングと技能チェック
- 3.測定手段の改善
- 4.測定手段の自動(自記)化
- 5.気づかれない方法(非干渉的方法)で測定を行う
- 対象者に気づかれない測定(非干渉的測定) unobtrusive measure を行うことができれば、対象者が意識的にデータを歪める可能性を排除することができます。たとえば、病院のカフェテリアにおける手指殺菌剤ディスペンサーの設置や手洗い奨励ポスターの効果を測るために、客の中に紛れて、他の客の行動を観察する、といったやり方がそれにあたります。
- 6.測定機器のキャリブレーション
- 測定機器の多く、特に機械的あるいは電気的な機器の場合には、ゴールドスタンダードを用いた定期的なキャリブレーションによって、その正確性を高めることができます。
- 7.盲検化 blinding(マスク化 masking)
- 盲検化は古典的な方法で、あらゆるバイアスに有効というわけではありませんが、選別的バイアスdifferentialbias(特定のグループの測定のみにバイアスが生じること)の排除には有効な手段です。2重盲検法 double blind test では、対象者のみならず、研究者にも、試験薬とプラセボのどちらに割り付けられたかがわからないようになっておき、たとえ何らかのバイアスが入り込んだとしても、その影響は試験薬群とプラセボ群の両者で全く等しいことになります。
妥当性
定義
妥当性 validity は、正確性に似た概念ですが、正確性が定量的な側面に着目しているのに対し、妥当性には、研究対象とする現象をその測定がどれほどよく代表しているかという、質的な側面が含まれています。たとえば、クレアチニンとシスタチンCは、いずれも腎臓から排泄される物質で、その血中濃度は、いずれも「正確」に(真値の1%の誤差で)測定することができますが、腎機能の指標として用いる場合には、シスタチンCの方がより「妥当」な指標となります。なぜなら、クレアチニンは、筋量によっても影響を受けるからです。
測定する内容によっては、ゴールドスタンダードを用いた評価が不可能な場合もあります。痛みや生活の質のように、主観的あるいは抽象的な現象を測定するスケールの場合は特にそうです。社会科学の分野では、そうした測定の妥当性を評価するための、いくつかの質的、量的基準が考案されています。
妥当性の種類
基準関連妥当性
基準関連妥当性 criterion-related validity は、新しい測定が、既存の評価の定まった測定とどれほどよく相関するかということです。たとえば胸部X線写真にもとづき胸水貯留量を予測する場合に、予測値と実際の胸水を抜いてみた実測値との相関を見ることがこれにあたります。このように、計測時点でほぼ同時に相関を見る場合を同時的妥当性 concurrent validity といいます。
予測妥当性
これに対し、予測妥当性 predictive validity は、その指標が、研究対象とするアウトカムの発生をどれほど正確に予測できるかということです。たとえば、うつ状態のスケール(尺度)が、その後の失業や自殺といった出来事をどれほど正確に予測できるかといったことです。この場合、失業などのイベントが発生したかどうかが明らかな基準値となります。このように基準関連妥当性と予測妥当性は明らかな答えがある場合にのみ検討できます。
構成概念妥当性
これに対し、構成概念妥当性 construct validity は、用いる測定が、研究対象とする理論的概念をいかに正しく表現し得ているかということです。たとえば、明らかに知的レベルが異なる2つの集団を、知能指数測定によって、正しく区別しうるかどうかといったことです。
構造概念妥当性は、特に明らかな外的基準がない場合に用いられます。たとえば、脳血管障害により生じた記憶障害の評価法を作成する場合、他の同様な記憶の評価法の成績との相関は高く、言語や視覚認知などの記憶以外の認知機能評価法の成績との相関は低いことが示されなければなりません。この場合、前者を収束的妥当性 convergent validity、後者を弁別的妥当性 discriminant validity とよびます。
上述の同時的妥当性と収束的妥当性との相違は、相関を調べる対象が同時的妥当性では明らかな外的基準であるのに対し、収束的妥当性では外的基準ではなく、同じ構成概念を計測していると考えられている評価尺度であるという点です。同じ構成概念を計測していると考えられている評価尺度がない場合には、近い構成概念を計測している評価尺度との関連を見るときもあります。たとえば、記憶障害の評価法の場合は、全般的知能の評価尺度との相関を見ることがこれにあたります。この場合は、相関係数はそれほど高くはなりません。
内容妥当性
内容妥当性 content validity とは、測定が、研究しようとする現象のさまざまな側面をどれほど反映しえているか、その程度を表す概念で、たとえば、QOLを評価する場合には、社会的、身体的、情緒的、あるいは知的な機能などの側面についての質問項目が含まれているかどうかといったことです。内容的妥当性の検討は統計解析ではなく、多くの専門家の判断を求めることにより行われることが多いです。
表面妥当性
表面妥当性 face validity は、その測定の本質的な適切性を表す概念で、たとえば、痛みを10項目のスケールで測定すること、社会階級を家庭所得で測定することが適切かどうかといったことです。≪被検者が評価内容からこの検査が何を測ろうとしているかが分かること≫と説明されることもあり、内容的妥当性の一側面とされていることが多いです。この表面的妥当性は被検者の反応に影響を与えます。原則としては何を測ろうとしているのかが被検者にはっきりとわかるほうが適切な回答を得やすいですが、たとえば性格の評価を行う場合などでは、まったく違うものを評価しているかのように被検者に思わせるほうが正しく評価できる場合もあります。
精度と正確性・妥当性の違い
正確性と妥当性は、共にバイアスの影響を受け、「測りたいと思っているものをちゃんと測れているか」を評価するという点に共通点があり、しばしば、両者の意味を「妥当性」の一語に含めることもあります(区別するときは、正確性は量的な側面、妥当性は質的な側面に着目しています)。
以下の図は、精度と正確性・妥当性を解説するのによく用いられる、両者の関係を概念的に示した図です。的の中央が真の姿、1つの弾の跡が1つの疫学研究の結果と考えます。
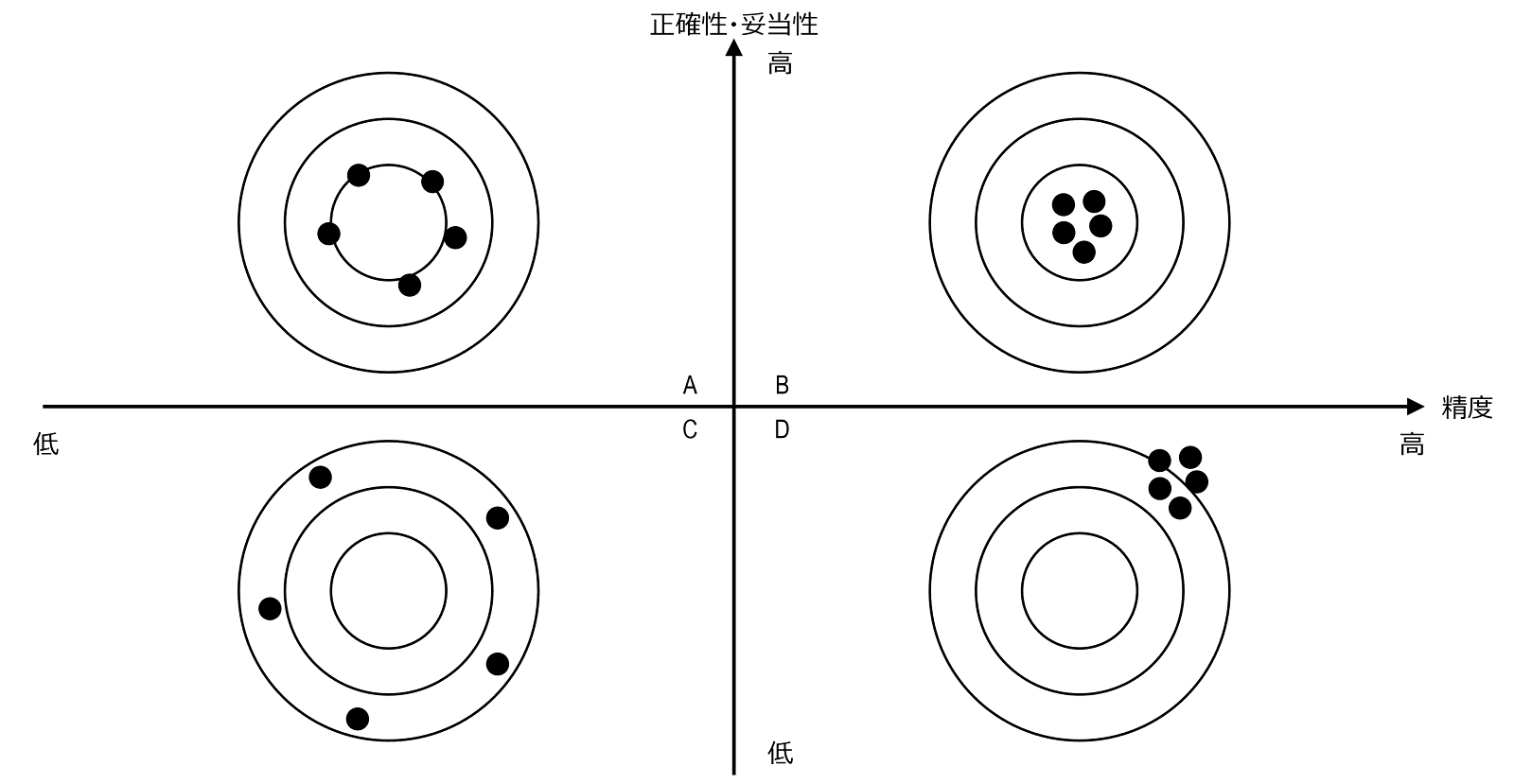
精度が低い場合(A・C)には、高い場合と比較して弾の跡があちこちに離れています。 これは偶然誤差が大きいため、弾の飛んでいく最初の方向は一定であっても、1つひとつの結果がバラバラになっていることを示しています。これに対し、精度が高い場合(B・D)、着弾点が固まっています。
正確性・妥当性が低い場合(C・D)には、銃身が的の中心(真の姿)ではなく、少しズレたところを向いていることが分かります。正確性・妥当性が高い場合(A・B)は、的の中心近くに着弾しています。
この図が示すように、研究によってなんらかの事実を明らかにする場合には、偶然誤差、系統誤差ともに小さくし、精度、正確性・妥当性の高いものとしなければなりません。
| 精度 | 正確性 | |
|---|---|---|
| 定義 | 繰り返し実施した測定の値の安定度(ばらつき) | 目的とする真の値に対する測定値の近さ |
| 評価方法 | 測定を繰り返して値の変動を調べる | ゴールドスタンダードとの比較 |
| 研究上の意義 | 効果検出の検出力を高める | 結論の妥当性(信憑性)を高める |
| 影響する要因 | 偶然誤差 | 系統誤差(バイアス) |
内的妥当性と外的妥当性
以上の「妥当性」、すなわち、測定値と真の値との関係は、内的妥当性 internal validity とよばれます。内的妥当性は、研究の中での比較の可能性を問題とするものです。
これに対し、外的妥当性 external validity という種類の妥当性も存在します。外的妥当性は研究結果を外挿するときの可能性を問題にしており、一般化可能性 generalizability ということもあります。つまり、「1つのターゲット集団で得られた結果が、他のターゲット集団でも該当するか」ということです。例えば、「人種が違うアメリカでの結果が日本でも当てはまるか?」という疑問が、外的妥当性に関するものです。
その定義から、外部妥当性を保証するためには、内部妥当性を満たしていることが必要条件となります。内部妥当性はすべての研究において必要な条件であり、「研究の目的である、本当にみたいものがきちんとみられているか」ということであるため、偶然誤差ではなく、バイアスを小さくする必要があります。
参考文献
- ケネス・ロスマン 著, 矢野 栄二, 橋本 英樹, 大脇 和浩 監訳. ロスマンの疫学. 篠原出版新社, 2013, p.177-179
- スティーブン・ハリー, スティーブン・カミングス ほか 著, 木原 雅子, 木原 正博 訳. 医学的研究のデザイン. メディカル・サイエンス・インターナショナル, 2014, p.116-121, p.37-49
- 丹後 俊郎, 小西 貞則 編集. 医学統計学の事典 新装版. 朝倉書店, 2018, p.88-89
- 中村 好一 著. 基礎から学ぶ楽しい疫学. 医学書院, 2020, p.87-95


{kind=link}
0 件のコメント:
コメントを投稿