
研究で得られた知見がどれほど母集団における真理を反映し得るかは、研究対象者(サンプル)の選び方に左右されます。サンプリングにおいては、対象者のリクルートに時間やコストがかかりすぎないこと、偶然誤差の影響をコントロールできるだけの十分な数を確保すること、できるだけ代表制の高い対象者を選ぶことなどが必要です。本稿では、代表性がありしかも研究可能な対象者を、どのように定義しサンプリングするか、対象者をどのようにリクルートするかについて解説します。
なお、閲覧にあたっては、以下の点にご注意ください。
- スマートフォンやタブレット端末でご覧の際、数式が見切れている場合は、横にスクロールすることができます。
調査・研究に関する「集団」の種類
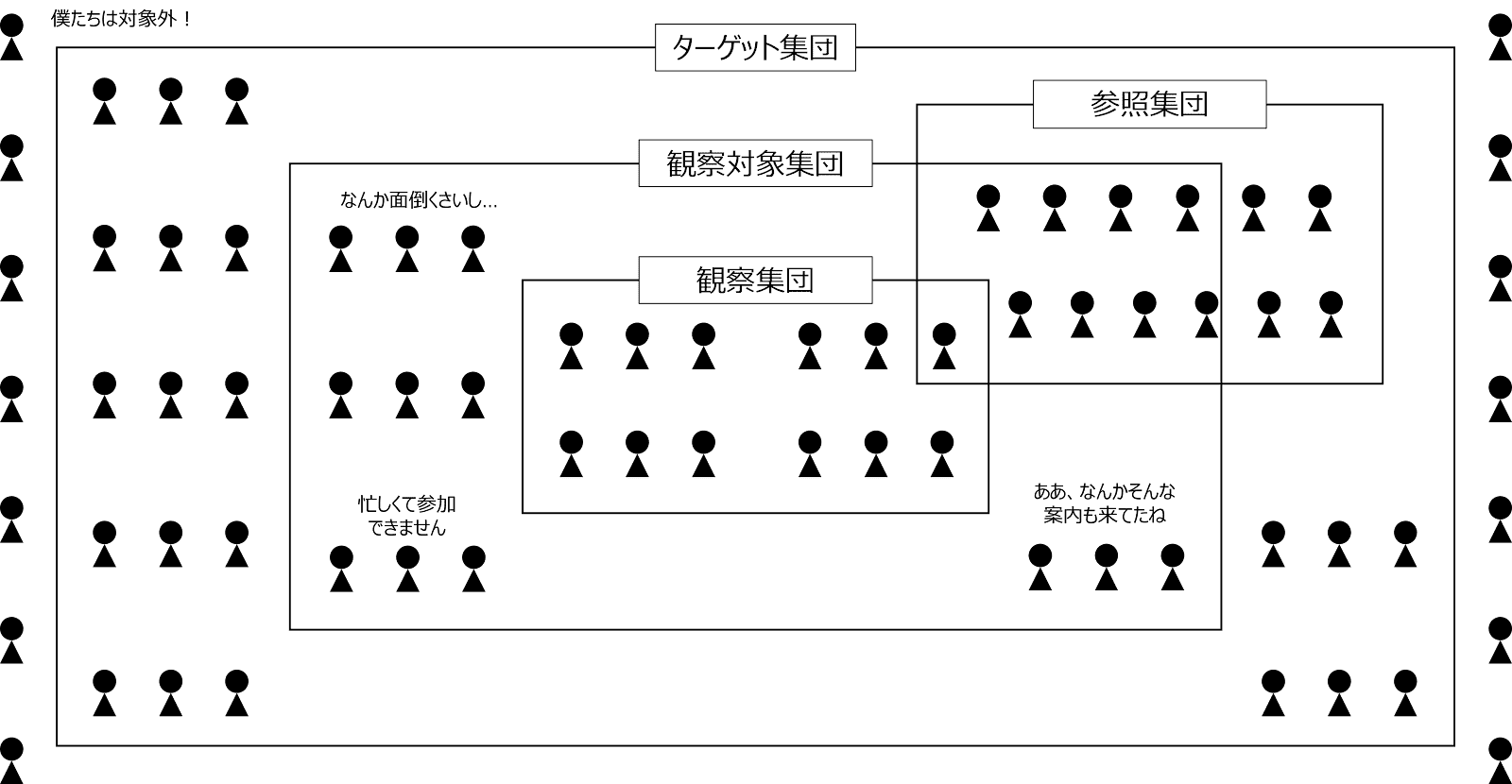
医学・疫学研究において、リサーチ・クエスチョンが決まると、対象とする母集団がそれに対応して決まります。リサーチ・クエスチョンが対象とする集団全体(研究の目的とする集団)のことを標的集団(目的母集団) target populationといい、例えば、「すべての10代の喘息患者」というように、研究結果を一般化しようとするすべての対象者の集合を指します。
ただ、実際には、ターゲット集団のすべてを調べることはできないので、誰を実際に研究の対象集団にするかを、検討しなければなりません。このとき、たとえば、「現在研究者の住む町に居住している10代の喘息患者」というように、ターゲット集団の中で、地理的にも時間的にも具体的に研究対象とすることが可能な一部の人々の集合を研究対象集団 accessible population、あるいは、観察対象集団 study population といいます(なお、日本における国勢調査など、ターゲット集団と観察対象集団が等しい調査を全数調査といいます)。
観察対象集団が決まると、その集団を対象として実際の調査・研究を行います。ただ、動物実験や試験管内の実験とは異なり、人を対象とする研究では、ほぼ必ず参加拒否者や未回答者が出てしまいます。観察対象集団から参加拒否を除いた、実際に研究に参加した集団を観察集団 examined population や実際の研究参加者 actual study sample といいます。
なお、標本調査では、後述するように、観察対象集団はターゲット集団から無作為抽出するのが原則ですが、「集めやすい」などの理由で、無作為抽出を行わない場合があります。例えば、ある地域の小学生の身体能力を調べたいときに、知人のスポーツクラブで調査をさせてもらうといった場合です。このとき、得られる結果は全体平均よりも高いことが予想される、いいかえると、この標本は「ターゲット集団の偏った一部」であると考えられます。このような場合、標本と同じ偏りをもった集団をターゲット集団内に想定し、その集団から無作為抽出を利用して標本が作られたと便宜的に考えることにします。このターゲット集団内に想定された(偏った)集団のことを参照集団 reference population と呼びます。「標本のデータから推測できる集団」と表現するとわかりやすいかもしれませんが、その想定には十分な配慮が必要となります。
研究対象者を決定するプロセス
研究を計画する場合、まずリサーチ・クエスチョンにふさわしい目的母集団の臨床的特性や各種属性を決め、次に、地理的・時間的な条件を加えて、目的母集団を代表し、かつ現実的にアクセス可能なサンプルへと絞り込んで行きます。
選択基準の確立
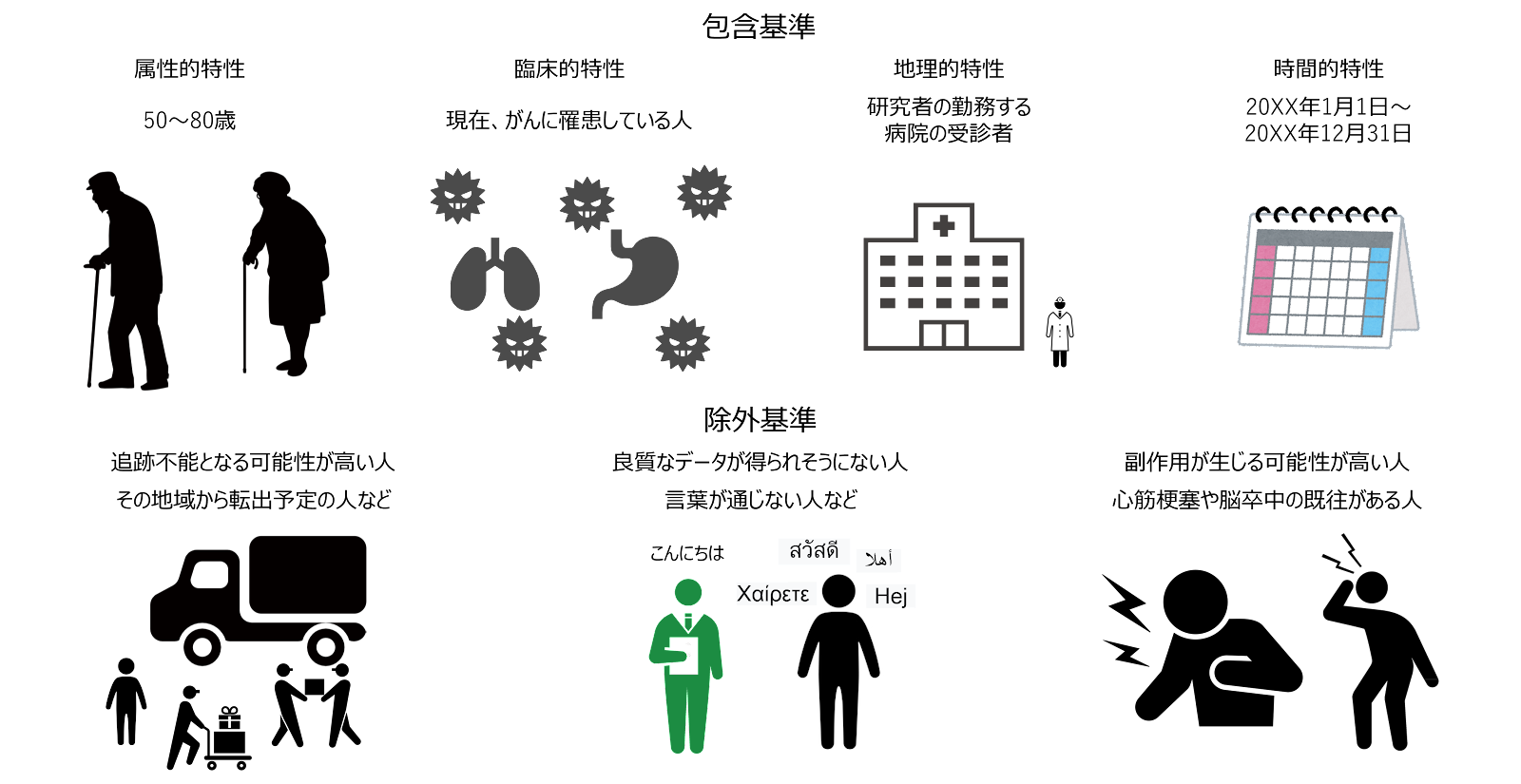
たとえば、高齢者のがんに対し、治療法Aと治療法Bのどちらがいいかを比較する研究を計画しているとします。その場合、研究者がまず行うべきことは、目的母集団を定義づける基準、つまり、選択基準 selection criteria(包含基準と除外基準の総称)を決定することです。
包含基準 inclusion criteria とは、目的母集団の主な特性を定義する条件を意味しますが、包含基準を決めることは難しい問題です。年齢は一般的に重要な要件となりますが、「70~79歳」というふうに対象を絞り込むと、より目的に適合する集団となる反面、研究の結果を適用できる患者さんが限定されてしまったり、研究を実現するうえで必要なサンプルサイズを確保できなくなってしまったりする可能性もあります。いっぽう、「50歳以上」のように条件を緩く設定すると、サンプルサイズは確保しやすくなりますが、例えば、強力な化学療法Aが弱い化学療法Bよりも優れているという結果が出たとして、果たして、50代の患者さんでも80代の患者さんでも同じことが言えるのかという疑問(交互作用が存在するかもしれない)という疑問が出てきてしまうことになります。
また、研究対象集団の包含基準を、地理的・時間的条件によって定義するときには、科学性と現実性のバランスに対する配慮が必要となります。研究者にとっては、自分の病院の患者を研究対象とするのが最も手軽でコストも小さくて済みますが、その場合には、受診者に偏りが生じ、得られた結果の一般化が難しくなるおそれがあることを考慮しなければなりません。包含基準の設定にあたって重要なことは、それがよく考え抜かれた上での判断であること、研究の途中で変更しなくて済むものであること、その研究成果の適用範囲を正確に判断できるよう明確に定義されたものであることです。
対象者を定義するとき、追跡を困難とするような疾患、たとえば、がんの転移のある患者は除かねばなりません。このように、追跡やデータの質、治療へのランダム割り付けを阻害するなどの理由で、除外要件を設定するとき、そうした条件のことを、除外基準exclusion criteria といいます。言語的障壁、心理学的問題、アルコール依存症、重篤な疾患なども、除外基準の例です。臨床試験と観察的研究が異なるのは、前者では、介入の安全性の観点から、除外基準を設けることが多いことです。たとえば、薬物の治験では、妊娠中の女性は一般に除外されます。ただし、研究を複雑にしたり、サンプル数の確保が難しくならないように、除外基準はなるべく少数にとどめなければなりません。
標本抽出法の種類
選択基準を満たす集団の規模はそのままでは大きすぎることが多いため、その中からサンプルを抽出しなければなりません。標本の抽出方法には大きく分けて、確率抽出法、あるいは無作為抽出法と非確率抽出法の2つがあります(これらについては、以下でより詳しく見ていきます)。
また、復元抽出法と非復元抽出法という区分もあります。復元抽出法 sampling with replacement とは、抽出した標本に同じ要素が重複して含まれる可能性がある方法で、非復元抽出法 sampling without replacement は、同じの要素が重複して抽出されないようにする方法です。要素を観察対象集団から選び出すときに、選ばれた要素を枠 frame から取り除かずに(あるいは戻して)抽出を続けるのが前者であり、取り除く(あるいは戻さずに行う)のが後者です。
現実には、ほとんどの研究が非復元抽出法で行われますが、厳密にいえば、非復元抽出法は、抽出方法によっては標準誤差の算出が困難となります。そこで、特に抽出率 sampling fraction が小さいときには、実際には非復元抽出法であっても標準誤差の算出が容易な復元抽出をしたものとみなし、標準誤差などを求めることがあります。
非確率抽出法
非確率抽出法 nonprobability sampling とは、ターゲット集団の特定の要素が選ばれる確率が高く、もしくは低くなっている(選ばれる確率がみな均一でない)抽出方法のことを指します。例えば、研究者が勤務している医療施設の患者や受診者を観察対象集団とする場合や調査の実施を周知し、研究に参加してくれるボランティアを募る場合がこれに当たります。非確率抽出法によるサンプルは、簡易サンプル convenience sample と呼ばれ、集めるためのコストが少なく、かつリクルートも容易なため、リサーチ・クエスチョンによっては非常に便利なサンプルとなります。
ただその反面、集まったサンプルから得られた結果にはバイアスがかかっている可能性が高く、一般化可能性は低くなるという短所もあります。サンプルを用いた研究からの推論が妥当かどうかは、リサーチ・クエスチョンの観点から見て、そのサンプルが、目的母集団を適切に代表するサンプルと言えるかどうかによりますが、非確率抽出サンプルの場合、それは研究者の判断の問題となります。

確率抽出法(無作為抽出法)
研究、とりわけ記述的研究においては、サンプルから得られた結果を母集団に一般化できるような科学性が求められます。その際のゴールドスタンダードとなるのが、確率抽出法 probability sampling、あるいは、無作為抽出法 random sampling です。これは、ターゲット集団を構成する全ての人が全く等しい確率で選ばれる(観察対象集団のメンバーとなる)サンプリング方法のことを指します。この方法は科学的であるため、選ばれたサンプルで観察された現象が、どれほどの代表性をもって母集団での現象を反映しているかを推定することや、標本誤差や統計学的有意性、信頼区間を計算することが可能となります。無作為抽出法にはいくつかの種類があります。
単純無作為抽出法
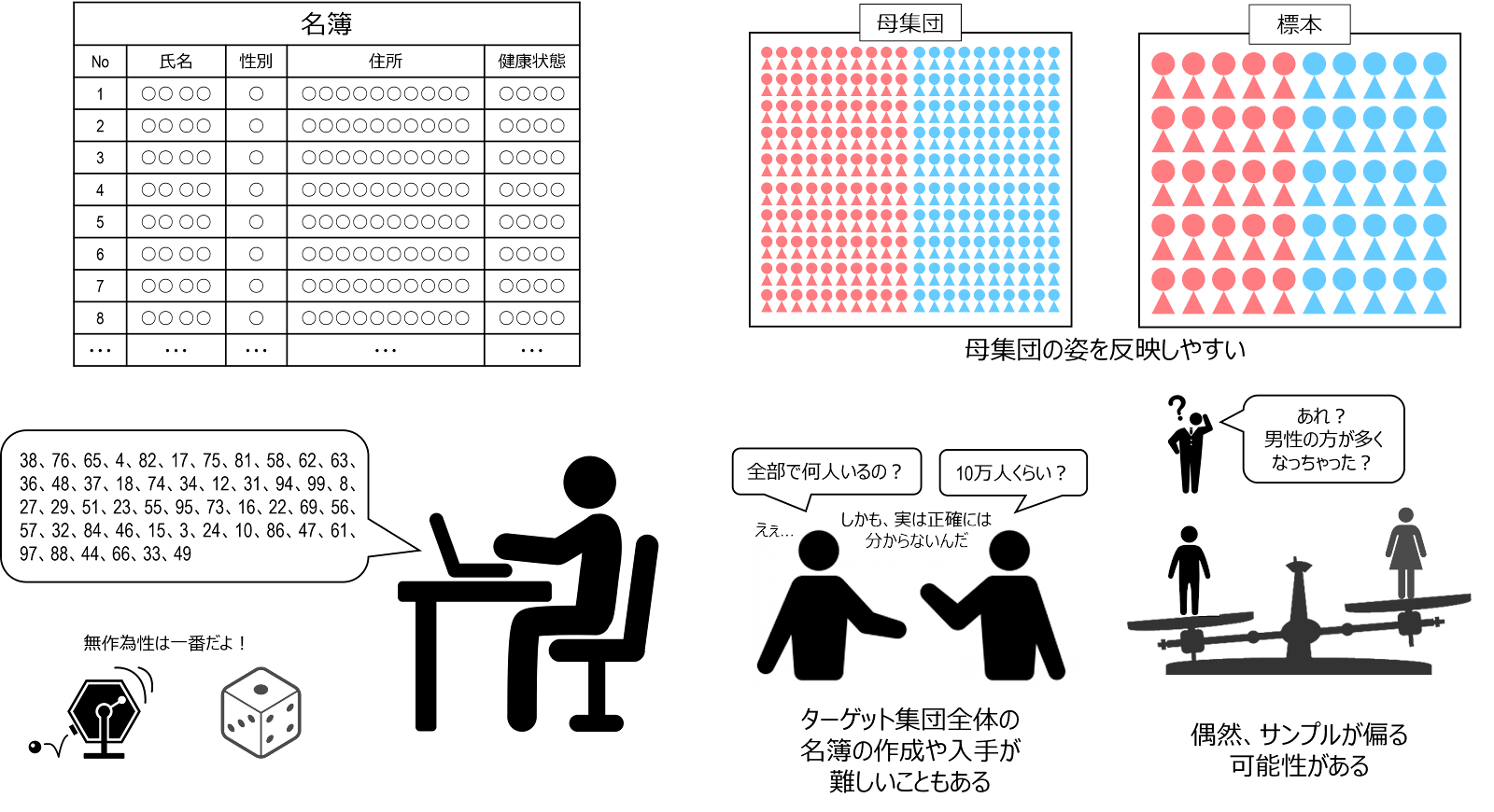
単純無作為抽出法 simple random sampling は、母集団の構成メンバー全員に通し番号をつけ、乱数表や乱数サイ、コンピュータが打ち出す乱数によって、標本を選んでいく方法です。
単純無作為抽出法は、「確率が等しい」という無作為性の保証は最も大きく、母集団の姿を反映しやすい方法です。また、原理が単純で、得られた標本の差異や誤差を評価しやすいことも長所といえます。
いっぽう、現実的にはターゲット集団の構成員全員が記載された名簿を入手することが難しかったり、母集団が大きいと、名簿の作成や標本の抽出までの準備に、手間がかかります。こうしたコストなどの問題から、ターゲット集団が大きな場合には実施が現実的でないことがあります。また、まったくの偶然で、サンプルが偏る可能性もあります。
系統抽出法
系統抽出法 systematic sampling は、最初に目的母集団の全員に番号をつけるところまでは同じですが、その後、何らかのあらかじめ定めた周期性(規則性)にしたがってサンプリングするという点で、単純無作為抽出法とは異なります。例えば、通し番号の下二桁を乱数表などで決定し、これに該当する者を標本としていくなどの方法がこれに該当します。
系統抽出法は、観察対象者を決定する際の手間が省けるという利点もありますが、サンプルの分布にたまたま何らかの周期性があった場合には、それがバイアスの原因となるという問題や、またサンプリング中に研究者が選び方を操作できるという問題があります。

層化抽出法
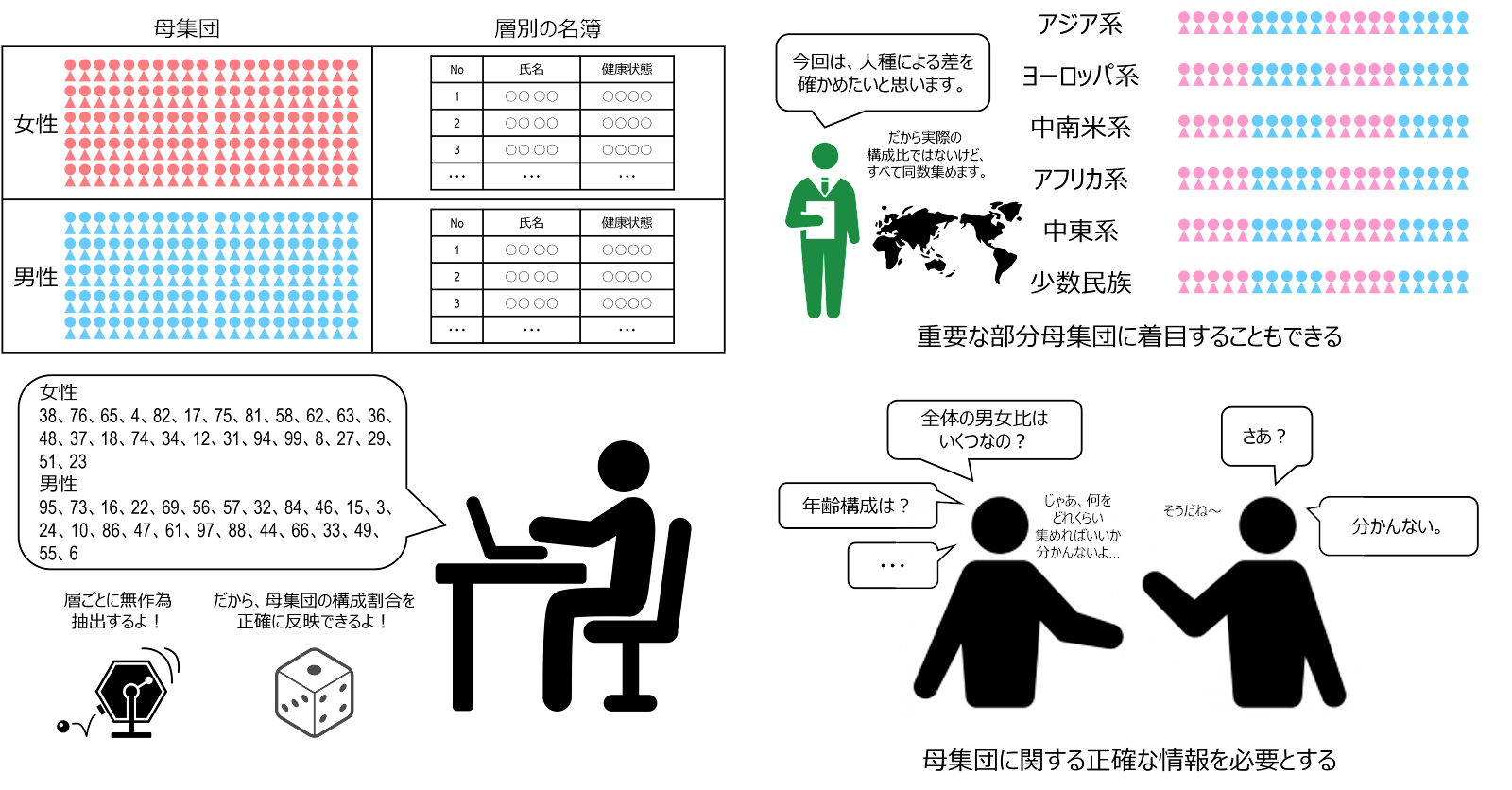
層化抽出法 stratified sampling は、母集団の構成メンバーをいくつかの層(たとえば、性、年齢階級、人種など)に分け、各層で無作為抽出を行う方法です。単純無作為抽出では、偶然の産物ではあるものの、特定の層に標本が偏ることがあり、これを避けるために採用されます。
調査する内容に関連する特性で分けることができると、より標本誤差は小さくなり、たとえ無意味な層別であっても、層別をしない場合の標本誤差よりも大きくなることはないため、規模の大きな調査では、何らかの層別が用いられることが多いとされています。
また、層化抽出法は、必ずしも各層の大きさに比例した数をサンプリングする必要はなく、小さな層であっても、研究上特に重要と思われる場合には、サンプル数を多くすることができます。妊娠中毒症の発生率を調べる研究を例に取れば、まず目的母集団を人種によって層化し、次に、各層から等しい数をサンプリングします。こうすれば、人口の少ない層からも多くのサンプルが得られるため、データの定度(精度)が増し、人種別の発生率が比較しやすくなります。
集落抽出法
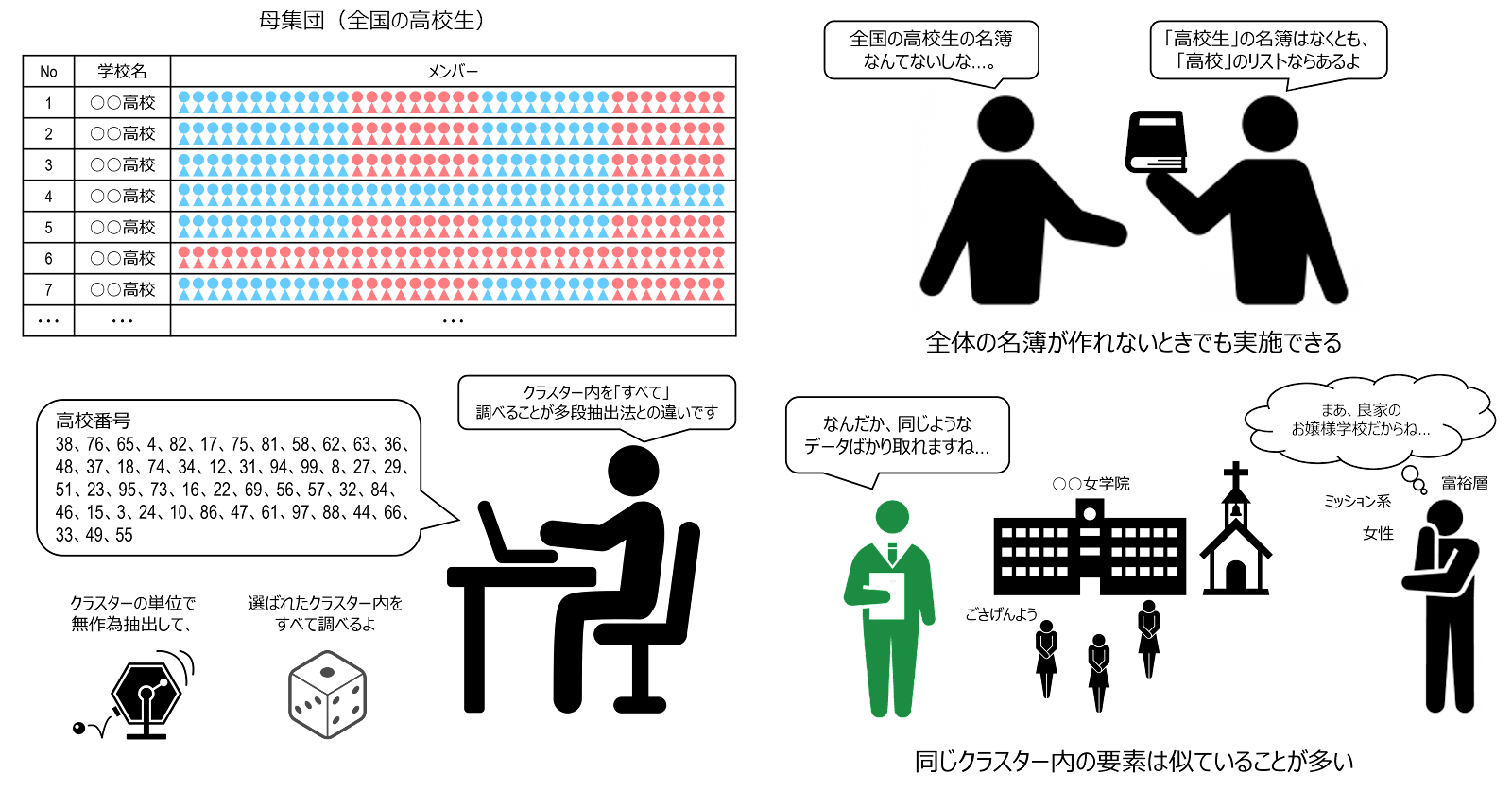
集落抽出法 cluster sampling は、母集団をいくつかの集団(例えば、学校や地区など)に区分したあと、その集団のうちいくつかを無作為抽出し、選ばれた集団の要素を全て調査する方法です。分けられた集団のことを「クラスター cluster」と呼ぶため、このような名称となっています。例えば、高校生を直接選ぶ代わりに高校を選び、抽出された高校に在籍するすべての高校生を標本とするという方法がこれに当たります。
集落抽出法は母集団が大規模かつ広域に分散していて、全体の対象者リストの作成が困難な場合に非常に有効な方法です。例えば、全国の入院患者を母集団とすると、全患者の一覧はふつう存在しませんが、病院のリストは入手可能であり、各病院では入院患者を把握しています。また、入院患者全体から個人を無作為抽出して、それぞれからデータを入手するよりも、病院をクラスターとみなして、ランダムに選び、選ばれた各医療機関からデータを集める方がはるかに時間的・経済的コストが小さくて済みます。
いっぽう、同じクラスター内の要素は似ている(級内相関係数 intraclass correlation coefficient が高い)ことが多く、集落抽出法は、標本誤差が大きくなりやすいという短所もあります。そのため、単純無作為抽出法と同じ精度の推定値を得るには、標本サイズをより大きくする必要があります。
多段抽出法
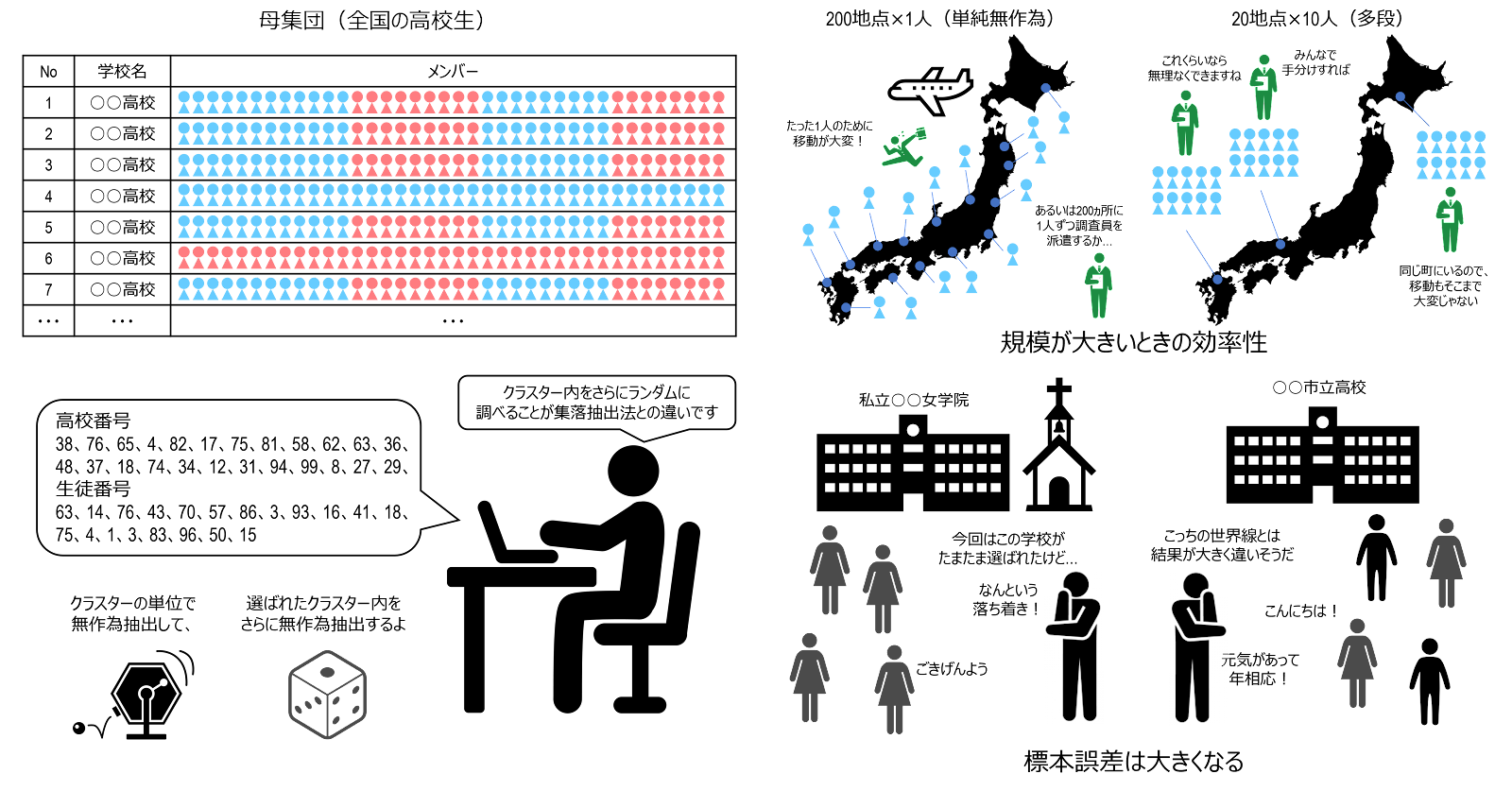
集落抽出法で選ばれた各クラスターにおいて、集落内のすべての要素を標本とするのではなく、さらにその一部を無作為抽出し、標本とする方法を2段抽出法 two-stage sampling といいます。例えば、選んだ病院のなかで患者をさらに抽出する場合や、最初に全国からいくつかの市区町村を選び、次に各市区町村内で住民を選ぶ場合などがこの例です。病院や市区町村といった1段目の抽出単位を第1次抽出単位 primary sampling unit と呼び、患者や住民といった2段目の抽出単位を第2次抽出単位 secondary sampling unit と呼びます。さらに、例えば学校から学級を選び、次に生徒を選ぶと3段抽出法となります。一般に、選ばれたクラスターのなかでさらに無作為抽出を繰り返していく方法を多段抽出法 multistage sampling と呼びます。
多段抽出法の最大のメリットは、対象者を訪問面接する際に、対象者が地点ごとにまとまっているため、調査員の移動距離が少なく、効率的に調査ができることです。
いっぽう、多段抽出法では、段の数が増えるほど標本誤差は大きくなりやすくなります。例えば、1段抽出で日本全国から高校生を直接選ぶよりも、一部の高校からのみ選び出す2段抽出の方が標本誤差は大きくなります。1段目でどの高校が選ばれるかによって推定値は大きく変わってしまうからです。そのため段の数は可能な限り増やさず、集落抽出法のときと同様に、クラスター内の均一性で補正した解析を行うなどの対応が必要となります。
参考文献
- 松井 敬 著. 標本調査論. 内田老鶴圃, 1990, 156p.
- 福井 武弘 著. 標本調査の理論と実際. 日本統計協会, 2013, 142p.
- スティーブン・ハリー, スティーブン・カミングス ほか 著, 木原 雅子, 木原 正博 訳. 医学的研究のデザイン:研究の質を高める疫学的アプローチ. 第4版, メディカル・サイエンス・インターナショナル, 2014, p.26-35
- 丹後 俊郎, 小西 貞則 編集. 医学統計学の事典 新装版. 朝倉書店, 2018, p.144-145
- 中村 好一 著. 基礎から学ぶ楽しい疫学. 医学書院, 2020, p.89-90


{kind=link}
0 件のコメント:
コメントを投稿